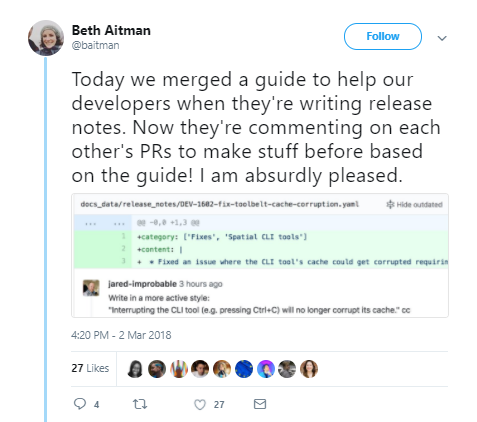
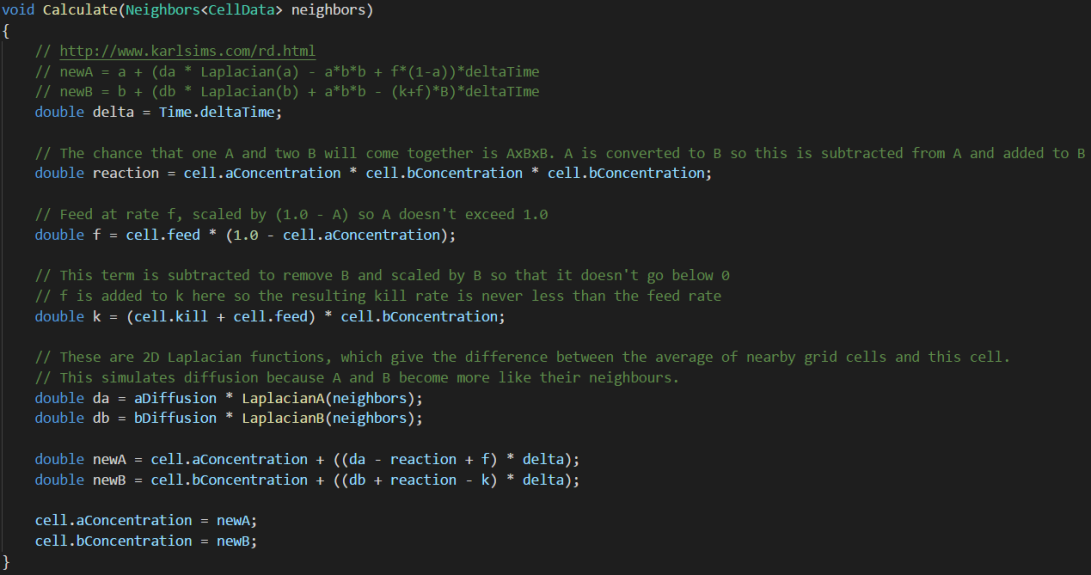
My first task this week was to fix the multiple player spawning problem. My solution to this was to have a simple bool in the client script which indicated whether a player had successfully spawned, as soon as this had been recorder, the bootstrapper would no longer send out any requests. This was needed because the bootstrapper relied on coroutines which were waiting for a period of time and then calling a function to request the player creation again. If a player was created during this wait period, once the coroutine had been started, the bootstrapper would end up spawning multiple players.
An additional fix here was to increase the timeout value to 60.0 seconds so that even in edge cases of extreme latency, the player should still spawn correctly. During this first task I happened across a workflow optimisation. Whenever I was making changes to test on the cloud I would rebuild the entire project, redeploy it to the cloud and re launch the client which takes a while (although I am speeding up at this process as I do it so regularly). I realised that if I was making a client specific change, there was no need to redeploy, I could just connect to the existing deployment. This more than halved the amount of redeployments I needed to do during this and the following tasks this week and I’m annoyed I didn’t realise it sooner in the project.
Now I had a functioning application I decided to look at the metrics to decide how best to start capturing them, I noticed a memory leak:
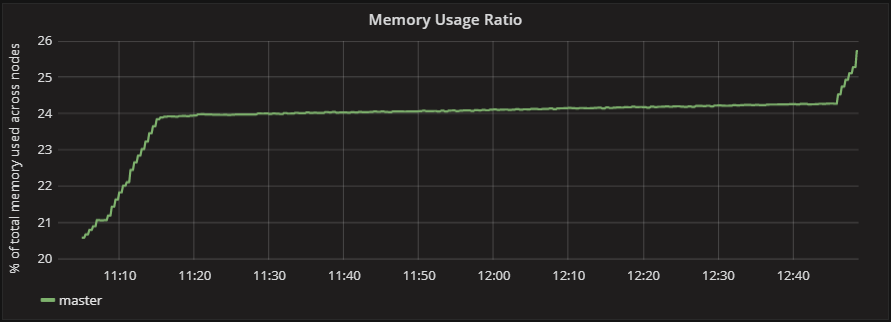
By observing the console in my client, I noticed I was getting fairly frequent warnings from unhandled query responses. I noticed that this seemed to be tied to the heartbeat functionality which was built into the player object of the base project, but decided I didn’t need it so cut it out.
This did appear to make a small improvement but I still definitely had a memory leak:
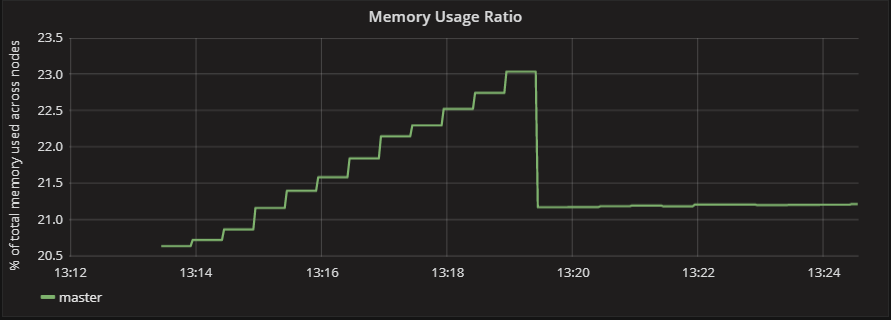
Digging around online I found that perhaps the number of component updates I was making was too high, and the workers were unable to handle them. I changed them from using a reliable delivery method to unreliable. This meant that if the network was under heavy load, the updates could be dropped.
Ideally, I would not have implemented this, as I would lose some degree of accuracy for the simulation, however some concessions are necessary and I felt like this is one of them. By removing the load of updates to the workers I was massively able to stem the flow of the memory leak:
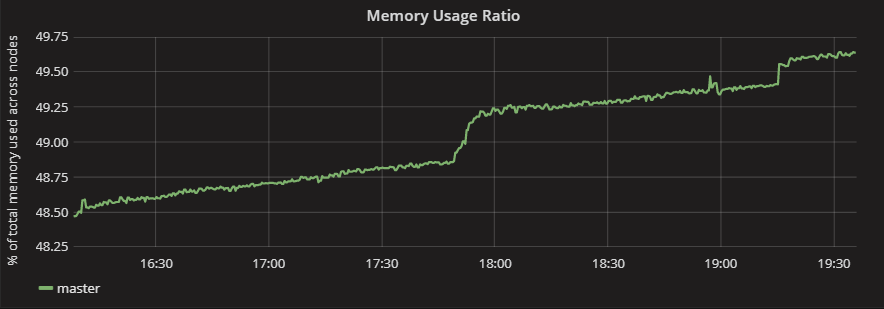
I increased the number of entities for this build which is why the precentage is higher, but the rate of increase appears to be slower. The jumps up here are when a client connects to the deployment. Even though the client disconnects, there is no indicator of this in the memory usage. This may need investigating as an optimisation but for now I think my simulation is ready to be used to gather baseline performance information.